Ch.01-1
# 인공지능(Artificial Intelligence)이란?
- 사람처럼 학습하고 추론할 수 있는 지능을 가진 시스템을 만드는 기술
# 머신러닝(Machine Learning)이란?
- 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야 (프로그래밍X, 규칙을 학습)
# 딥러닝(Deep Learning)이란?
- 인공 신경망(artificial neural network)을 기반으로 한 방법들
Ch.01-2
# 구글 코랩(Google Colab)

Ch.01-3
# k-최근접 이웃 알고리즘(K-Nearest Neighbors Algorithm)
1. 데이터 준비 - 지도 학습 알고리즘이므로, 데이터 포인트와 라벨(클래스)을 포함하는 학습 데이터셋이 필요
2. 거리 측정 - 예측하려는 새로운 데이터 포인트와 학습 데이터셋의 모든 포인트간의 거리를 계산
3. 이웃 선택 - k개의 가장 가까운 데이터 포인트를 선택
4. 결정 - 선택된 k개의 이웃 중 가장 많은 클래스를 가진 클래스로 분류(다수결 원칙)


cf) scikit-learn 메서드 종류
fit() -> 사이킷런 모델을 훈련할 때 사용하는 메서드
predict() -> 사이킷런 모델을 훈련하고 예측할 때 사용하는 메서드
score() -> 훈련된 사이킷런 모델의 성능을 측정
Ch.02-1
# 머신러닝 알고리즘
- 지도 학습: 입력(데이터)과 타깃(정답)으로 이뤄진 훈련 데이터로 학습
- 비지도 학습: 정답이 없는 훈련 데이터로 학습 -> 예측하는 것이 아닌 입력 데이터에서 어떤 특징을 찾는 데 활용
# 훈련 세트와 테스트 세트



샘플링 편향(sampling bias) 문제에서 벗어나 훈련 세트와 테스트 세트에 클래스0과 1이 잘 섞여 있는 것을 확인할 수 있음!
Ch.02-2
# scikit-learn을 이용해 train set과 test set으로 나누기

무작위로 데이터를 나누었을 때 샘플이 골고루 섞이지 않아 샘플링 편향 문제가 발생할 수 있음
-> stratify 매개변수를 이용해보자!

이 부분만 train_test_split() 안에 추가해주면 클래스 비율에 맞게 데이터를 나누게 됨.
# 데이터 전처리가 필요한 이유?
- length가 25, weight가 150인 class0에 속하는가 class 1에 속하는가?
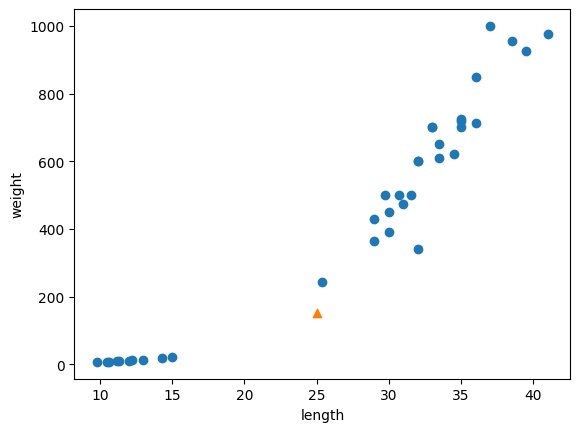

- 왜 이런 문제가 발생하는가? x축과 y축의 범위가 다르기 떄문이다. -> 스케일(scale)을 같도록 하자!
<표준점수>로 변환해서 모델을 다시 훈련시키면...




'IT > 혼자 공부하는 머신러닝+딥러닝' 카테고리의 다른 글
| <혼자 공부하는 머신러닝+딥러닝> Chapter 03 (0) | 2024.07.14 |
|---|
